blog
入茶した話
2025-05-11 追記 この話はなかったことになりました(詳細)。
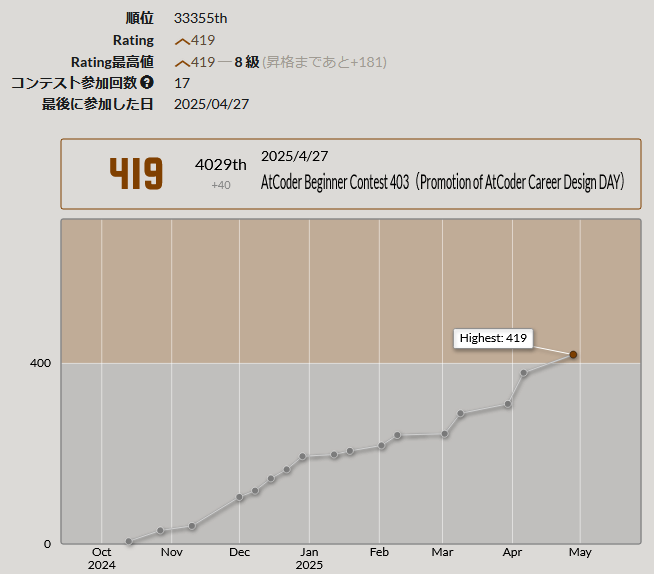
AtCoderをはじめて7ヵ月、2025年4月27日のABC403(3完)でようやく入茶しましたので入茶記事とやらを書いてみます。
自己紹介
はじめまして。 Kito、あるいはQvitoと名乗っております。 高専の電子情報系学科の5年生です。 もともと授業でCでの手続きプログラミングとアルゴリズム、グラフを少しやっていたくらいでほぼアルゴリズムについてはほぼ知識はありませんでした。 現在は主にC++23を使っています。
競プロの学習について
主に学習に使用したのは以下のものです。
- AtCoder Beginners Selection
- AtCoder Problems
- ChatGPT・Gemini
- その他Webサイト
ほかにEDPCと競プロ典型90問を少しやっています。
AtCoder Beginners Selection
名前の通り、初心者向けの練習問題集です。 コンテストに出る前はこれをやっていました。 競プロに必要な初歩の技術が身につくため、かなり役に立ちました。 プログラム言語の知識があれば6問目くらいまでは解けると思います。 後半になってくると灰色上位や茶色、緑色の問題が出てくるため、少し難しいと思います。実際、”Otoshidama”と”Traveling”は解けませんでした。
Atcoder Problems
有志の方が作成しているAtCoderの過去問集です。 公式サイトだと過去問がわかりにくいのもあって、かなり精進に役立っています。 方法としては、サイト上で目についた問題を解いてみるとか、”User”タブ上の”Recommendation”からレートをもとにおすすめされる問題を解いてみるとかしています。 どれだけ問題を解いたかなどが可視化できたりかなり高機能なので、モチベーションの維持にもつながり、なくてはならない存在となっています。 “Virtual Contests”という、過去問から問題を選んでコンテストを開催できる機能があるのですが、なかなか使う機会がなく、いつか使ってみたいと思っています。
ChatGPT・Gemini
C++の言語仕様や問題の解法、エラーの原因などを調べるのに使っています。 マジックハンドのようなもので、自分の手(知能)に届かない場所にある問題に手が届くようになる魔法の道具です。 コンテスト中は禁止なので使っていません。
その他Webサイト
QiitaやZennなどにわかりやすい記事を書いてくれている人がたくさんいるのでありがたく使わせていただいています。
高専の授業で既習の内容で役に立ったこと
プログラム言語の知識
高専ではCをメインにJavaとPythonを少しやったくらいなのですが、基本どんなプログラム言語も大して変わらないので、C++にも応用できました。 ただ、競プロはクラスなどをほぼ使わないのでプログラム言語の学習には向いていないのかなとも思います。
アルゴリズムの知識
授業で探索(DFS, BFS)と動的計画法、ソート、木の概要を学習していました。 ただ、実装となると大変で、いまだに動的計画法とBFSの問題を本番で解いたことがありません。 まじめに勉強しておけばよかったと後悔しています。 ほかには、構文解析で出てきた括弧構造の判定を使いました(ABC394 D)。
AtCoder で学習したもの
書き洩らしたやつがたくさんあると思いますが、思いつくのはこんな感じです。 茶色になるために学習する内容の参考になればいいかなと思います。
多分身についているもの
-
DFS
日本語で深さ優先探索といい、バックトラックのうち深く潜っていく探索方法です。 再帰で簡単に書けるため身につきました。
-
UnionFind
グラフの連結成分の判定と管理に使える構造です。 書けといわれて書けるかというと書けないのですが、使い方と理論はだいたいわかります。
-
unordered_set
C++の標準ライブラリにあるハッシュ集合です。 灰色のうちは集合を使うような問題は順序がいらない問題が主だったのでsetではなくunordered_setを使用しています。要素数を $N$ としたとき時間計算量がsetは $O(\log N)$ なのに対してunordered_setは $O(N)$ であるため順序がいらないのならおすすめです。
-
unordered_map
C++の標準ライブラリにあるハッシュの連想配列です。unordered_setとほぼ一緒です。
-
stack, queue
C++の標準ライブラリにあります。だいたいvectorでできると思っています。
-
イテレータ
データの並びを抽象化したもので、いろいろな構造に使えます。神機能。
名前と概要を知っているもの
-
累積和
配列Aがあるとき、 $S_i = \sum^{i}_{k=0} A_k$ をとったSが累積和です。 区間和を高速に求められるので必須なのですが、自分で書くとバグります。
-
Segment Tree
高速に区間演算ができます。 概要はわかりますが、今まで使ったことはありません。Lazy Segment Treeも同様。
-
二分探索
単調なデータがあったとき、 $O(\log N)$ で探索できます。中央の値より右にあるか左にあるかを見ます。C++だったらsetで簡単にできます。
-
動的計画法
部分問題を計算してそれをもとに大きい部分問題を計算するアルゴリズムです。
反省点など
考察が弱い
愚直な問題は解けるのですが、枝刈りが必要な問題や、数学的に読み替えが必要な問題に気づかないことが多く、時間がかかる、そもそも解けないということが多いです(ABC397 D, ABC400 C, etc)。 改善したいのですが、コンテスト中になるとなかなかできないものです。
そもそも数学が弱い
数学問題がそもそも苦手で、確率や組み合わせなどの問題が解けていません(ABC392 D, etc)。 高専1年生の基礎数学の復習が必要なのかなと思っています。
アルゴリズムの学習の問題
解説やTwitterの解法などを見て、アルゴリズムを知ることが多いのですが、概要だけ調べて、upsolveしなかったり、手を動かして実装しなかったりが多いため、アルゴリズムが身につかないという問題点があります。 ただの怠慢なのですが、実際学んでおけばよかったという場面はよくあります。 ただ、実力にあっていないアルゴリズムを身に着けるのは時間的に効率がよくないのではないかという気持ちもあり、難しいところです。
グリッド問題が弱い
二次元の情報が与えられる問題が苦手で、加湿器の回(ABC383)はA問題しか解けませんでした。だいたいはただのグラフ問題で探索で解けるといえばそうなのですが、なんとなく苦手意識があり飛ばしてしまうことが多くなっています。
今後
これからは、反省点の内容をできるだけ早期に修正しつつ、未履修のアルゴリズムの学習を行っていきたいと思っています。あとは夏のうちに緑に入りたいですね。
ABC403参加記録
A問題 Odd Position Sum
入力を読み取り奇数番目の値を足していけばOKです。
int main(){
intin(N); // int N; cin >> N;
int ans = 0;
rep(i, N){ // for(int i = 0; i < N; i++){
intin(A);
if(not(i&1))ans += A;
}
outbr(ans); // cout << ans << " " << "\n";
}
B問題 Four Hidden
二重forループで文字列を比較するだけです。
比較に関しては?ならばtrueにしてあげる必要があります。
ワイルドカードというやつですね。
int main(){
string T, U;
in(T, U); // cin >> T >> U;
rep(i, int(T.length()-U.length() + 1)){
bool flag = true;
rep(j, int(U.length())){
if(T[i+j] == '?' || T[i+j] == U[j]);
else flag = false;
}
if(flag == true){
judicium(true); // cout << (true ? "Yes" : "No") << "\n";
return 0;
}
}
judicium(false); // cout << (false ? "Yes" : No) << "\n";
}
C問題 403 Forbidden
権限を個別に持っているユーザを集合の配列で持ってあげます。 それとは別にすべてのページの権限を持っているユーザの集合を別に管理することで高速に処理できます。コンテスト中権限を英訳できなかったので変数名が悲惨なことになっています。
int main(void){
intin(N, M, Q);
vector<uset<int>> user(N+1); // vector<unordered_set<int>> ...
uset<int> all;
rep(Q){
intin(query);
if(query == 1){
intin(X, Y);
user[X].insert(Y);
}
else if(query == 2){
intin(X);
all.insert(X);
}
else{
intin(X, Y);
judicium(all.contains(X) || user[X].contains(Y));
}
}
}
D問題 Forbidden Difference
差が $D$ になるペアを書き出してどうにかできないかなと思ったけどどうにもできなかった。
E問題 Forbidden Prefix
multisetで辞書順で管理し、 $X$ の挿入時に $Y$ の $S$ より右側の、$Y$ の挿入時の $X$ の $S$ より左側の文字列を順にみて数え上げようとして失敗。 lower_bound, upper_boundを忘れていたのが敗因の可能性。
F問題 Shortest One Formula
DPっぽそうだなと思い、実装方針が思いつかないので退散。 ABCでBNF記法が出てくるとは思っていなかった。
感想
思ったよりもあっさり入茶したので実感がわかないのですが、とてもうれしいと思っています。 本当はABC400で入茶したかったのでそこだけは悔しいと思っています。
お礼
読んでいただき、ありがとうございます。至らないところもありますが、今後も精進してまいりますためよろしくお願いします。